TLDR: I made a game of snake in which you control the snake by pointing your head. It uses your device’s camera and a pretrained TensorFlow model to estimate the direction your head is pointing in.
A week ago or so I decided to take on a hobby programming project. I wanted to make something involving machine learning that was somehow interactive, and I wanted it to run in the browser so that it could be hosted with GitHub pages to minimise worries about servers.
I knew that one of the clever things about TensorFlow is that it makes it relatively straightforward to run a trained model on various platforms, so I looked into TensorFlow.js as a way to run models in the browser.
As a first mini-project in this direction, I made a digit-classifier trained using MNIST. Here’s a demo:

You can see the live version here, and the code on GitHub here.
Training the model was nothing new to me, but having never properly learned JavaScript, there were many things that I had to learn by debugging. Here are a few things I learned about: drawing on a canvas; converting a canvas into a grid of pixels; asynchronous functions (I still don’t understand how to properly deal with promises and “thenable” objects to be honest); disabling pull-to-refresh.
Now armed with the knowledge of how to actually run TensorFlow models in the browser, I decided to make something slightly less trivial. While looking through the TensorFlow.js examples, I saw a demo of a model that estimates the geometry of faces from 2D images. I thought this was cool and wanted to make something with it!
The simplest non-trivial thing I could think of was to use the model to estimate the direction that the user’s head was pointing in — up, down, left, right or straight ahead. I had previously made a game of snake as a warm-up JavaScript exercise and thought it would be cool to be able to play by moving your head rather than using the keyboard to control the snake. Here’s a demo:
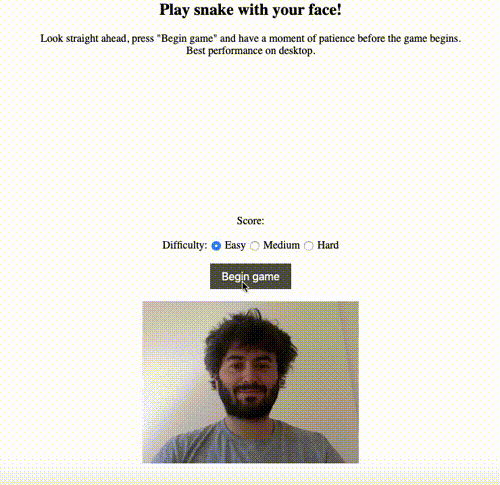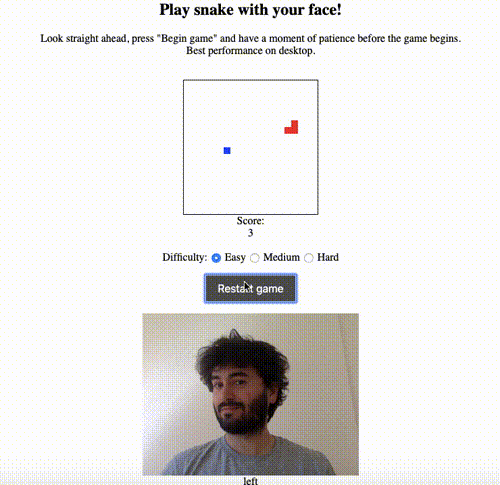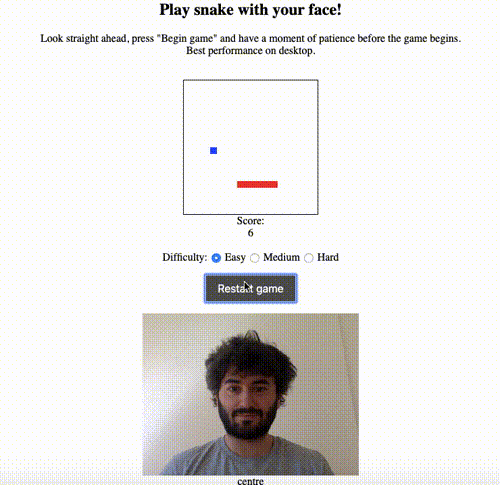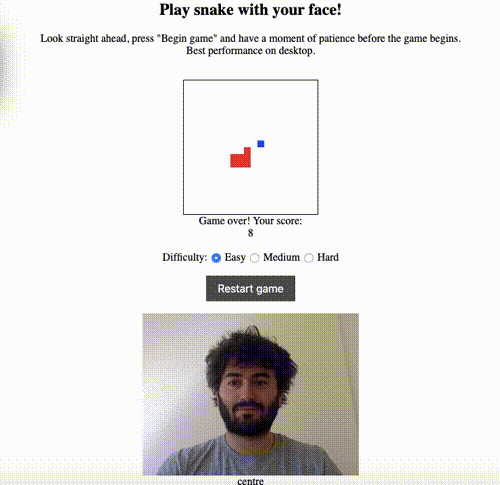
The live version is here, and the code is on GitHub here.
I’ll briefly explain in the rest of this post how the head-direction estimation works. (The actual snake part of this is just straightforward basic JavaScript, so I won’t discuss that here.)
The face mesh model from the TensorFlow.js examples accepts an image as input and outputs estimates of the 3-dimensional locations of ~400 facial landmarks. These points form the vertices of a mesh that describes the face. For instance, there are ~10 points determining the boundaries of the upper and lower lips and each eyelid. Although the model outputs locations for all of these landmarks, we only make use of a few.
The high level idea is to model the face as a flat plane, and to estimate the normal vector of this plane. That vector points in the direction that the face is looking. To find the normal vector of any plane, you can take any two non-parallel vectors lying in the plane and take their cross product.
Here, we locate the centre of the mouth by averaging the coordinates of the lip landmarks. We also locate the left and right cheeks, and consider the vectors lip -> left cheek and lip -> right cheek. The cross product gives us roughly the direction the face is pointing. (This is a 3D vector with x denoting left-right, y denoting up-down, and z denoting in/out of the screen.)
This is a very crude way to model the face, so if the vector we calculated has a positive y-component, it doesn’t necessarily mean that the user is actually looking up. So we introduce another heuristic to detect which direction the snake should move.
At the beginning of the game, the user is asked to look straight ahead, giving a reference vector. Subsequent estimated vectors are compared to this reference. If the y coordinate has increased/decreased by a sufficiently significant amount relative to the reference, the direction is classified as up/down respectively. Similarly, if the x coordinate has increased/decreased by a sufficiently significant amount relative to the reference, the direction is classified as left/right respectively. (In the case that both x and y coordinates changed significantly, the left/right direction takes precedence, and ‘sufficiently significant’ is a parameter that has to be chosen.)
It’s very crude, but because this is an interactive game, the user adapts to the algorithm, so we don’t have to worry too much to get something that works (of course, if this were part of a product we’d have to worry a lot more about everything working smoothly).
There are still several things to improve. First, it’s not as responsive as I’d like. I presume this is because it takes some time to execute the model and estimate the face landmark locations. Also, the refresh rate can’t be too high or my laptop fan starts to whirr. Clearly it should be possible to improve on this, since we aren’t using almost all of the information output by the model being used! Second, it doesn’t work great on mobile, I presume because of the less powerful computational resources available. It would be great to dive into using the specialised hardware on some new phones (e.g. The newest Pixel’s Neural Core and the iPhone’s Bionic chip), but that’s a project for another day.
 are encoded as the prior distribution, so the latent representation
are encoded as the prior distribution, so the latent representation  contains no information about
contains no information about 
 gives the full objective to be maximised:
gives the full objective to be maximised:![\displaystyle \mathcal{L}({\theta}, {\phi}, x) = \underbrace{\mathbb{E}_{z \sim q_{\phi}(z|x)}\log p_{\theta}(x|z)}_{\text{(i)}} - \underbrace{\text{KL}[q_{\phi}(z|x) || p(z)]}_{\text{(ii)}} \leq \log p_{\theta}(x)\quad (*)](http://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathcal%7BL%7D%28%7B%5Ctheta%7D%2C+%7B%5Cphi%7D%2C+x%29+%3D+%5Cunderbrace%7B%5Cmathbb%7BE%7D_%7Bz+%5Csim+q_%7B%5Cphi%7D%28z%7Cx%29%7D%5Clog+p_%7B%5Ctheta%7D%28x%7Cz%29%7D_%7B%5Ctext%7B%28i%29%7D%7D+-+%5Cunderbrace%7B%5Ctext%7BKL%7D%5Bq_%7B%5Cphi%7D%28z%7Cx%29+%7C%7C+p%28z%29%5D%7D_%7B%5Ctext%7B%28ii%29%7D%7D+%5Cleq+%5Clog+p_%7B%5Ctheta%7D%28x%29%5Cquad+%28%2A%29&bg=ffffff&fg=000&s=1 "\displaystyle \mathcal{L}({\theta}, {\phi}, x) = \underbrace{\mathbb{E}_{z \sim q_{\phi}(z|x)}\log p_{\theta}(x|z)}_{\text{(i)}} - \underbrace{\text{KL}[q_{\phi}(z|x) || p(z)]}_{\text{(ii)}} \leq \log p_{\theta}(x)\quad (*)")
") .
.") we can get a tractable lower bound of the desired objective, giving us the VAE objective. The variational lower bound is precisely what its name suggests – a lower bound on the log-likelihood, not a ‘regularised reconstruction cost’. A failure to recognise this distinction has caused confusion to many.
we can get a tractable lower bound of the desired objective, giving us the VAE objective. The variational lower bound is precisely what its name suggests – a lower bound on the log-likelihood, not a ‘regularised reconstruction cost’. A failure to recognise this distinction has caused confusion to many.") and parameterised family of conditional distributions
and parameterised family of conditional distributions }") , the latter of which is also called the decoder or generator interchangeably in the literature.
, the latter of which is also called the decoder or generator interchangeably in the literature. , we get a distribution
, we get a distribution  = \int p_{\theta}(x|z) p(z) dz}") over the data-space. Training an LVM requires (a) picking a divergence between
over the data-space. Training an LVM requires (a) picking a divergence between }") and the true data distribution
and the true data distribution }") ; (b) choosing
; (b) choosing ![\displaystyle \text{KL}[p_{\text{data}} || p_{\theta}] = \mathbb{E}_{x\sim p_{\text{data}}} \log p_{\text{data}}(x) - \mathbb{E}_{x\sim p_{\text{data}}} \log p_{\theta}(x),](http://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Ctext%7BKL%7D%5Bp_%7B%5Ctext%7Bdata%7D%7D+%7C%7C+p_%7B%5Ctheta%7D%5D+%3D+%5Cmathbb%7BE%7D_%7Bx%5Csim+p_%7B%5Ctext%7Bdata%7D%7D%7D+%5Clog+p_%7B%5Ctext%7Bdata%7D%7D%28x%29+-+%5Cmathbb%7BE%7D_%7Bx%5Csim+p_%7B%5Ctext%7Bdata%7D%7D%7D+%5Clog+p_%7B%5Ctheta%7D%28x%29%2C&bg=ffffff&fg=000&s=1 "\displaystyle \text{KL}[p_{\text{data}} || p_{\theta}] = \mathbb{E}_{x\sim p_{\text{data}}} \log p_{\text{data}}(x) - \mathbb{E}_{x\sim p_{\text{data}}} \log p_{\theta}(x),")
 is a divergence, we have that
is a divergence, we have that ![{\text{KL}[p_{\text{data}} || p_{\theta}] \geq 0}](http://s0.wp.com/latex.php?latex=%7B%5Ctext%7BKL%7D%5Bp_%7B%5Ctext%7Bdata%7D%7D+%7C%7C+p_%7B%5Ctheta%7D%5D+%5Cgeq+0%7D&bg=ffffff&fg=000000&s=1 "{\text{KL}[p_{\text{data}} || p_{\theta}] \geq 0}") with equality if and only if
with equality if and only if  . This means that the maximum possible value of
. This means that the maximum possible value of }") occurs when
occurs when  = \mathbb{E}_{x\sim p_{\text{data}}} \log p_{\text{data}}(x)}") . So this is the global optimum of the VAE objective.
. So this is the global optimum of the VAE objective.}") and
and }") can’t easily be evaluated, but the variational lower bound of this quantity,
can’t easily be evaluated, but the variational lower bound of this quantity, ") , can be. This involves introducing a new family of conditional distributions
, can be. This involves introducing a new family of conditional distributions }") which we call the approximate posterior. Provided we have made sensible choices about the family of distributions
which we call the approximate posterior. Provided we have made sensible choices about the family of distributions }") and the approximate posterior
and the approximate posterior ![\log p_{\theta}(x) = \mathcal{L}({\theta}, {\phi}, x) + \text{KL}[q_{\phi}(z|x) || p_{\theta}(z|x)] \geq \mathcal{L}({\theta}, {\phi}, x) \quad (**)](http://s0.wp.com/latex.php?latex=%5Clog+p_%7B%5Ctheta%7D%28x%29+%3D+%5Cmathcal%7BL%7D%28%7B%5Ctheta%7D%2C+%7B%5Cphi%7D%2C+x%29+%2B+%5Ctext%7BKL%7D%5Bq_%7B%5Cphi%7D%28z%7Cx%29+%7C%7C+p_%7B%5Ctheta%7D%28z%7Cx%29%5D+%5Cgeq+%5Cmathcal%7BL%7D%28%7B%5Ctheta%7D%2C+%7B%5Cphi%7D%2C+x%29+%5Cquad+%28%2A%2A%29&bg=ffffff&fg=000&s=1 "\log p_{\theta}(x) = \mathcal{L}({\theta}, {\phi}, x) + \text{KL}[q_{\phi}(z|x) || p_{\theta}(z|x)] \geq \mathcal{L}({\theta}, {\phi}, x) \quad (**)")
") and think ‘reconstruction + regulariser’ as many people do, it’s important to remember that the encoder
and think ‘reconstruction + regulariser’ as many people do, it’s important to remember that the encoder  if there exists a
if there exists a  such that
such that  = p_{\text{data}}(x)}") for all
for all }") and that we use a Gaussian decoder, where
and that we use a Gaussian decoder, where  = \mathcal{N}(\mu_{\theta}(z), \Sigma_{\theta}(z))}") where
where  and
and  are parameterised by neural networks. In this case, the decoder is also powerful with respect to
are parameterised by neural networks. In this case, the decoder is also powerful with respect to  = \mu_{\text{data}}}") and
and  = \Sigma_{\text{data}}}") .
.") that ‘ignoring the latent variable’ in VAEs with decoders that are powerful with respect to the data is actually optimal behaviour.
that ‘ignoring the latent variable’ in VAEs with decoders that are powerful with respect to the data is actually optimal behaviour. such that
such that  such that
such that  = p(z)}") for all z. Then
for all z. Then }") is a globally optimal solution to the VAE objective.
is a globally optimal solution to the VAE objective. = p(z)}") , and thus
, and thus ![{\text{KL}[p_{\theta^*}(z|x) || q_{\phi^*}(z|x) ] = 0}](http://s0.wp.com/latex.php?latex=%7B%5Ctext%7BKL%7D%5Bp_%7B%5Ctheta%5E%2A%7D%28z%7Cx%29+%7C%7C+q_%7B%5Cphi%5E%2A%7D%28z%7Cx%29+%5D+%3D+0%7D&bg=ffffff&fg=000000&s=1 "{\text{KL}[p_{\theta^*}(z|x) || q_{\phi^*}(z|x) ] = 0}") and so the variational lower bound in Equation
and so the variational lower bound in Equation ![\begin{aligned}\log p_{\theta^*}(x) &= \mathcal{L}({\theta^*}, {\phi^*}, x) \\&= \mathbb{E}_{z \sim q_{\phi^*}(z|x)} [ \log p_{\theta^*}(x|z) ] + \text{KL}[q_{\phi^*}(z|x) || p(z)] \\&= \log p_{\text{data}}(x)\end{aligned}](http://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D%5Clog+p_%7B%5Ctheta%5E%2A%7D%28x%29+%26%3D+%5Cmathcal%7BL%7D%28%7B%5Ctheta%5E%2A%7D%2C+%7B%5Cphi%5E%2A%7D%2C+x%29+%5C%5C%26%3D+%5Cmathbb%7BE%7D_%7Bz+%5Csim+q_%7B%5Cphi%5E%2A%7D%28z%7Cx%29%7D+%5B+%5Clog+p_%7B%5Ctheta%5E%2A%7D%28x%7Cz%29+%5D+%2B+%5Ctext%7BKL%7D%5Bq_%7B%5Cphi%5E%2A%7D%28z%7Cx%29+%7C%7C+p%28z%29%5D+%5C%5C%26%3D+%5Clog+p_%7B%5Ctext%7Bdata%7D%7D%28x%29%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=1 "\begin{aligned}\log p_{\theta^*}(x) &= \mathcal{L}({\theta^*}, {\phi^*}, x) \\&= \mathbb{E}_{z \sim q_{\phi^*}(z|x)} [ \log p_{\theta^*}(x|z) ] + \text{KL}[q_{\phi^*}(z|x) || p(z)] \\&= \log p_{\text{data}}(x)\end{aligned}")

 = p_{\text{data}}(x)}") but
but }") isn’t independent of
isn’t independent of  ?
? such that
such that  = p_{\text{data}}(x)}") and for which
and for which }") does actually depend on
does actually depend on  . In this case, for any
. In this case, for any  we have
we have![\begin{aligned}\mathcal{L}({\theta^*}, {\phi^*}, x) &= \log p_{\text{data}}(x) \\&= \log p_{\theta^+}(x) \\&= \mathcal{L}({\theta^+}, {\phi}, x) + \text{KL}[q_{\phi}(z|x) || p_{\theta^+}(z|x)] \\&\geq \mathcal{L}({\theta^+}, {\phi}, x)\end{aligned}](http://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D%5Cmathcal%7BL%7D%28%7B%5Ctheta%5E%2A%7D%2C+%7B%5Cphi%5E%2A%7D%2C+x%29+%26%3D+%5Clog+p_%7B%5Ctext%7Bdata%7D%7D%28x%29+%5C%5C%26%3D+%5Clog+p_%7B%5Ctheta%5E%2B%7D%28x%29+%5C%5C%26%3D+%5Cmathcal%7BL%7D%28%7B%5Ctheta%5E%2B%7D%2C+%7B%5Cphi%7D%2C+x%29+%2B+%5Ctext%7BKL%7D%5Bq_%7B%5Cphi%7D%28z%7Cx%29+%7C%7C+p_%7B%5Ctheta%5E%2B%7D%28z%7Cx%29%5D+%5C%5C%26%5Cgeq+%5Cmathcal%7BL%7D%28%7B%5Ctheta%5E%2B%7D%2C+%7B%5Cphi%7D%2C+x%29%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=1 "\begin{aligned}\mathcal{L}({\theta^*}, {\phi^*}, x) &= \log p_{\text{data}}(x) \\&= \log p_{\theta^+}(x) \\&= \mathcal{L}({\theta^+}, {\phi}, x) + \text{KL}[q_{\phi}(z|x) || p_{\theta^+}(z|x)] \\&\geq \mathcal{L}({\theta^+}, {\phi}, x)\end{aligned}")
}") will be strictly worse than the global optimum for any
will be strictly worse than the global optimum for any ![{\text{KL}[q_{\phi}(z|x) || p_{\theta^+}(z|x)] > 0}](http://s0.wp.com/latex.php?latex=%7B%5Ctext%7BKL%7D%5Bq_%7B%5Cphi%7D%28z%7Cx%29+%7C%7C+p_%7B%5Ctheta%5E%2B%7D%28z%7Cx%29%5D+%3E+0%7D&bg=ffffff&fg=000000&s=1 "{\text{KL}[q_{\phi}(z|x) || p_{\theta^+}(z|x)] > 0}") . If
. If }") is likely to be complex. Since
is likely to be complex. Since ![{\text{KL}[q_{\phi}(z|x) || p_{\theta^+}(z|x)] = 0}](http://s0.wp.com/latex.php?latex=%7B%5Ctext%7BKL%7D%5Bq_%7B%5Cphi%7D%28z%7Cx%29+%7C%7C+p_%7B%5Ctheta%5E%2B%7D%28z%7Cx%29%5D+%3D+0%7D&bg=ffffff&fg=000000&s=1 "{\text{KL}[q_{\phi}(z|x) || p_{\theta^+}(z|x)] = 0}") for all
for all  , and hence it is likely that for any
, and hence it is likely that for any  < \mathcal{L}({\theta^*}, {\phi^*}, x)")
 = p_{\text{data}}(x)}") will be preferred by the VAE over
will be preferred by the VAE over  = p_{\text{data}}(x)}") — without using the latent variables, this will be preferred by the VAE.
— without using the latent variables, this will be preferred by the VAE. to maximise
to maximise ") where
where  are the observed data. The fact that we are maximising the product of the
are the observed data. The fact that we are maximising the product of the ") corresponds to an assumption that each
corresponds to an assumption that each ") .
.")
") for a single data point
for a single data point ") , so that out objective can be written
, so that out objective can be written = \log \left( \int p_\theta(x|z) p(z) dz \right)") .
.") , multiply the inside of the integral by
, multiply the inside of the integral by }{q(z)}") and rearrange without changing its value. (This has a strong connection to Importance Sampling, see below.) Thus we can rewrite our objective as
and rearrange without changing its value. (This has a strong connection to Importance Sampling, see below.) Thus we can rewrite our objective as = \log \left( \int p_\theta(x|z) \frac{p(z)}{q(z)} q(z) dz \right)") .
. is concave and the integral can be written as an expectation, we can use Jensen’s inequality to swap the
is concave and the integral can be written as an expectation, we can use Jensen’s inequality to swap the  . This results in a (variational) lower bound consisting of terms we can evaluate, provided we have chosen
. This results in a (variational) lower bound consisting of terms we can evaluate, provided we have chosen ![\begin{aligned} \log p_\theta(x) &= \log \left( \mathbb{E}_{q(z)} p_\theta(x|z) \frac{p(z)}{q(z)} \right) \\&\geq \mathbb{E}_{q(z)} \left[ \log p_\theta(x|z) + \log p(z) - \log q(z) \right] \\&=\mathbb{E}_{q(z)} \left[ \log p_\theta(x|z) \right] - \text{KL}\left[q(z) || p(z) \right] \end{aligned}](http://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Clog+p_%5Ctheta%28x%29+%26%3D+%5Clog+%5Cleft%28+%5Cmathbb%7BE%7D_%7Bq%28z%29%7D+p_%5Ctheta%28x%7Cz%29+%5Cfrac%7Bp%28z%29%7D%7Bq%28z%29%7D+%5Cright%29+%5C%5C%26%5Cgeq+%5Cmathbb%7BE%7D_%7Bq%28z%29%7D+%5Cleft%5B+%5Clog+p_%5Ctheta%28x%7Cz%29+%2B+%5Clog+p%28z%29+-+%5Clog+q%28z%29+%5Cright%5D+%5C%5C%26%3D%5Cmathbb%7BE%7D_%7Bq%28z%29%7D+%5Cleft%5B+%5Clog+p_%5Ctheta%28x%7Cz%29+%5Cright%5D+-+%5Ctext%7BKL%7D%5Cleft%5Bq%28z%29+%7C%7C+p%28z%29+%5Cright%5D+%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=1 "\begin{aligned} \log p_\theta(x) &= \log \left( \mathbb{E}_{q(z)} p_\theta(x|z) \frac{p(z)}{q(z)} \right) \\&\geq \mathbb{E}_{q(z)} \left[ \log p_\theta(x|z) + \log p(z) - \log q(z) \right] \\&=\mathbb{E}_{q(z)} \left[ \log p_\theta(x|z) \right] - \text{KL}\left[q(z) || p(z) \right] \end{aligned}")
 . This is the notation you’ll often see in the literature, (e.g.
. This is the notation you’ll often see in the literature, (e.g. ![\begin{aligned} \log p_\theta(x) &\geq \mathbb{E}_{q_\phi(z|x)} \left[ \log p_\theta(x|z) \right] - \text{KL}\left[q_\phi(z|x) || p(z) \right] =: \mathcal{L}(x, \theta, \phi) \end{aligned}](http://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Clog+p_%5Ctheta%28x%29+%26%5Cgeq+%5Cmathbb%7BE%7D_%7Bq_%5Cphi%28z%7Cx%29%7D+%5Cleft%5B+%5Clog+p_%5Ctheta%28x%7Cz%29+%5Cright%5D+-+%5Ctext%7BKL%7D%5Cleft%5Bq_%5Cphi%28z%7Cx%29+%7C%7C+p%28z%29+%5Cright%5D+%3D%3A+%5Cmathcal%7BL%7D%28x%2C+%5Ctheta%2C+%5Cphi%29+%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=1 "\begin{aligned} \log p_\theta(x) &\geq \mathbb{E}_{q_\phi(z|x)} \left[ \log p_\theta(x|z) \right] - \text{KL}\left[q_\phi(z|x) || p(z) \right] =: \mathcal{L}(x, \theta, \phi) \end{aligned}")
![\begin{aligned} &\log p_\theta(x) - \mathcal{L}(x, \theta, \phi)\\&=\log p_\theta(x) - \mathbb{E}_{q_\phi(z|x)} \left[ \log p_\theta(x|z) \right] + \text{KL}\left[q_\phi(z|x) || p(z) \right] \\&= \mathbb{E}_{q_\phi(z|x)} \left[\log p_\theta(x) - \log p_\theta(x|z) + \log q_\phi(z|x) - \log p(z) \right] \\&= \mathbb{E}_{q_\phi(z|x)} \left[\log p_\theta(x) - \log \frac{p_\theta(z|x) {p_\theta(x)}}{p(z)} + \log q_\phi(z|x) - \log p(z) \right] \\&= \mathbb{E}_{q_\phi(z|x)} \left[\log q_\phi(z|x) - \log p_\theta(z|x) \right] \\&= \text{KL}\left[q_\phi(z|x) || p_\theta(z|x) \right]\end{aligned}](http://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%26%5Clog+p_%5Ctheta%28x%29+-+%5Cmathcal%7BL%7D%28x%2C+%5Ctheta%2C+%5Cphi%29%5C%5C%26%3D%5Clog+p_%5Ctheta%28x%29+-+%5Cmathbb%7BE%7D_%7Bq_%5Cphi%28z%7Cx%29%7D+%5Cleft%5B+%5Clog+p_%5Ctheta%28x%7Cz%29+%5Cright%5D+%2B+%5Ctext%7BKL%7D%5Cleft%5Bq_%5Cphi%28z%7Cx%29+%7C%7C+p%28z%29+%5Cright%5D+%5C%5C%26%3D+%5Cmathbb%7BE%7D_%7Bq_%5Cphi%28z%7Cx%29%7D+%5Cleft%5B%5Clog+p_%5Ctheta%28x%29+-+%5Clog+p_%5Ctheta%28x%7Cz%29+%2B+%5Clog+q_%5Cphi%28z%7Cx%29+-+%5Clog+p%28z%29+%5Cright%5D+%5C%5C%26%3D+%5Cmathbb%7BE%7D_%7Bq_%5Cphi%28z%7Cx%29%7D+%5Cleft%5B%5Clog+p_%5Ctheta%28x%29+-+%5Clog+%5Cfrac%7Bp_%5Ctheta%28z%7Cx%29+%7Bp_%5Ctheta%28x%29%7D%7D%7Bp%28z%29%7D+%2B+%5Clog+q_%5Cphi%28z%7Cx%29+-+%5Clog+p%28z%29+%5Cright%5D+%5C%5C%26%3D+%5Cmathbb%7BE%7D_%7Bq_%5Cphi%28z%7Cx%29%7D+%5Cleft%5B%5Clog+q_%5Cphi%28z%7Cx%29+-+%5Clog+p_%5Ctheta%28z%7Cx%29+%5Cright%5D+%5C%5C%26%3D+%5Ctext%7BKL%7D%5Cleft%5Bq_%5Cphi%28z%7Cx%29+%7C%7C+p_%5Ctheta%28z%7Cx%29+%5Cright%5D%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=1 "\begin{aligned} &\log p_\theta(x) - \mathcal{L}(x, \theta, \phi)\\&=\log p_\theta(x) - \mathbb{E}_{q_\phi(z|x)} \left[ \log p_\theta(x|z) \right] + \text{KL}\left[q_\phi(z|x) || p(z) \right] \\&= \mathbb{E}_{q_\phi(z|x)} \left[\log p_\theta(x) - \log p_\theta(x|z) + \log q_\phi(z|x) - \log p(z) \right] \\&= \mathbb{E}_{q_\phi(z|x)} \left[\log p_\theta(x) - \log \frac{p_\theta(z|x) {p_\theta(x)}}{p(z)} + \log q_\phi(z|x) - \log p(z) \right] \\&= \mathbb{E}_{q_\phi(z|x)} \left[\log q_\phi(z|x) - \log p_\theta(z|x) \right] \\&= \text{KL}\left[q_\phi(z|x) || p_\theta(z|x) \right]\end{aligned}")
![\log p_\theta(x) = \mathcal{L}(x, \theta, \phi) + \text{KL}\left[q_\phi(z|x) || p_\theta(z|x)\right] \geq \mathcal{L}(x, \theta, \phi)](http://s0.wp.com/latex.php?latex=%5Clog+p_%5Ctheta%28x%29+%3D+%5Cmathcal%7BL%7D%28x%2C+%5Ctheta%2C+%5Cphi%29+%2B+%5Ctext%7BKL%7D%5Cleft%5Bq_%5Cphi%28z%7Cx%29+%7C%7C+p_%5Ctheta%28z%7Cx%29%5Cright%5D+%5Cgeq+%5Cmathcal%7BL%7D%28x%2C+%5Ctheta%2C+%5Cphi%29&bg=ffffff&fg=000&s=1 "\log p_\theta(x) = \mathcal{L}(x, \theta, \phi) + \text{KL}\left[q_\phi(z|x) || p_\theta(z|x)\right] \geq \mathcal{L}(x, \theta, \phi)")
") . For a fixed
. For a fixed ") with respect to
with respect to ![\text{KL}\left[q_\phi(z|x) || p_\theta(z|x)\right]](http://s0.wp.com/latex.php?latex=%5Ctext%7BKL%7D%5Cleft%5Bq_%5Cphi%28z%7Cx%29+%7C%7C+p_%5Ctheta%28z%7Cx%29%5Cright%5D&bg=ffffff&fg=000&s=1 "\text{KL}\left[q_\phi(z|x) || p_\theta(z|x)\right]") . This is why
. This is why  p(z) dz") by
by ") and estimate the integral as
and estimate the integral as  p(z) dz = \mathbb{E}_{p(z)}p_\theta(x|z) \approx \frac{1}{k}\sum_{i=1}^k p_\theta(x|z_i)") .
.") will have extremely large variance.
will have extremely large variance. p(z) dz &= \int p_\theta(x|z) \frac{p(z)}{q(z)} q(z) dz \\ &= \mathbb{E}_{q(z)}p_\theta(x|z) \frac{p(z)}{q(z)} \\&\approx \frac{1}{k}\sum_{i=1}^k p_\theta(x|z_i)\frac{p(z_i)}{q(z_i)} \qquad z_1, \ldots, z_k \sim q(z) \end{aligned}")
 = p_\theta(z|x)") — the posterior distribution over
— the posterior distribution over \frac{p(z)}{p_\theta(z|x)} &= p_\theta(x|z)\frac{p(z)p_\theta(x)}{p_\theta(x|z)p(z)} \\ &=p_\theta(x)\end{aligned}")
") we would draw, our one-sample Monte Carlo estimator would give the correct answer. Unfortunately, calculating
we would draw, our one-sample Monte Carlo estimator would give the correct answer. Unfortunately, calculating ") , so this insight doesn’t give us a trick to quickly calculate
, so this insight doesn’t give us a trick to quickly calculate \frac{p(z)}{p_\theta(z|x)}") is constant in
is constant in }p_\theta(x|z) \frac{p(z)}{p_\theta(z|x)}") is the expectation of a constant function and thus
is the expectation of a constant function and thus = \log\left(\mathbb{E}_{p_\theta(z|x)}p_\theta(x|z) \frac{p(z)}{p_\theta(z|x)}\right) = \mathbb{E}_{p_\theta(z|x)} \log\left( p_\theta(x|z) \frac{p(z)}{p_\theta(z|x)}\right)")
 = p_\theta(z|x)") . This equation says that this bound is tight when the approximate posterior is equal to the true posterior, which we already learned above.
. This equation says that this bound is tight when the approximate posterior is equal to the true posterior, which we already learned above.